Take a Look at the World-Renowned Supercomputers Inside UT’s Texas Advanced Computing Center

Inside a large building on UT’s J.J. Pickle Research Campus is a room the size of a grocery store in a mid-sized town. In that room sits row after row of racks, 7 feet tall, each holding stacks of black central processing units. It is tempting to write that these CPUs are quietly figuring out the secrets of the universe, but quiet they are not. All conversations in this room must be shouted, as the whirring of thousands of fans makes it as loud as a sawmill. They are on the job around the clock—no bathroom breaks, no weekends, no holidays.
This is the Data Center, the roaring heart of the Texas Advanced Computing Center (TACC), which for 23 years has been at the forefront of high-powered computing and a jewel in the crown of The University of Texas at Austin.
“Supercomputer” is an informal term, but it’s “a good Texas concept”: Our computer is bigger than yours, muses Dan Stanzione, TACC’s executive director and associate vice president for research at UT Austin for the past decade. Almost every supercomputer today is built as an amalgam of standard servers, and it is when servers are clustered together that they become supercomputers.
Supercomputing at the University dates to the late 1960s, with mainframes on the main campus. The center that became UT’s Oden Institute for Computational Science and Engineering, a big contributor, was started in 1973 by Tinsley Oden. In the mid-1980s, Hans Mark, who had started the supercomputing program at NASA, became UT System chancellor and took a keen interest in its advancement. But funding withered through the 1990s. Everything was rebooted, so to speak, when TACC was founded in 2001, “with about 12 staffers and a hand-me-down supercomputer,” recalls Stanzione.

TACC operates three big platforms, named Frontera, Stampede3, and Lonestar6, in addition to a few experimental systems, many storage systems, and visualization hardware. In a given year, Frontera, the biggest computer, will work on about 100 large projects. Other machines, such as Stampede3, will support several thousand smaller projects annually.
Stanzione explains that computing speed has increased by a factor of 1,000 every 10 to 12 years since the late 1980s. In 1988, a gigaFLOPS—1 billion floating-point operations per second—was achieved. The first teraFLOPS was reached in 1998. A petaFLOPS (1 quadrillion) happened in 2008. An exaFLOPS (1 quintillion) was reached in 2022. Next up is the zetaFLOPS, which might be reached in fewer than 10 years.
Stanzione says that over the last 70 to 80 years, this increase could be attributed roughly in thirds: a third physics, a third architecture (how the circuits and computers were built), and a third algorithms (how the software was written). But those are now changing as we bump up against the limits of physics. There was a time when making the transistor smaller would roughly double the performance, but now chips have become so small that the gates of the newest transistors are only 10 atoms wide, which results in more leakage of electrical current. “They’re so small that the power goes up and the performance and speed doesn’t necessarily go up,” Stanzione says.
The average American home runs on about 1,200 watts. TACC, by comparison, typically requires about 6 megawatts, with a maximum capacity of 9 megawatts. (A megawatt is 1 million watts, or 1,000 kilowatts.) Frontera, TACC’s biggest machine, alone uses up to 4.5 megawatts, and the entire center uses the equivalent of about 5,000 homes.
“The turbines at Mansfield Dam, full power, are 30 megawatt turbines, so we could use a third of the capacity of the dam just in the Data Center now,” Stanzione says, with a blend of astonishment, swagger, and concern. “We’re going to add another 15 megawatts of power in the new data center that we’re building out because the next machine will be 10 megawatts.”
TACC’s new data center under construction in Round Rock will be powered completely by wind credits. Round Rock, where I-35 crosses SH-45, has become a hotspot for data centers because that is where fiber-optic lines, which run along I-35, enter a deregulated part of Central Texas.
To mitigate the energy used by these hungry machines, TACC uses wind credits to buy much of its power from the City of Austin. A hydrogen fuel cell nearby on the Pickle Campus also supplies power, so we “have a fair mix of renewables,” Stanzione says.
The first thing you notice upon entering the Data Center is that it is cold. The faster the machines, the more power they require, the more cooling they require. TACC once air-cooled the machines at 64.5 degrees, but you can only pull through so much air before you start having “indoor hurricanes,” Stanzione says. “We were having 30 mph wind speeds.”
Spreading the servers out would help the heat dissipate but would require longer cables between them. And even though the servers are communicating at the speed of light, as pulses shoot down a fiber-optic cable—“which is about a foot per nanosecond (one-billionth of a second) or, in good Texas-speak, 30 nanoseconds per first down,” he says—“if we spread them out, then we’re taking these very expensive computers and making them wait.” Those billionths of a second add up.
In 2019, when its fastest computer was using 60,000 watts per rack, TACC switched to liquid cooling, in which a coolant is piped over the face of the chip. Horizon, the next system, will use 140,000 watts per cabinet of GPUs (graphics processing units). Now they have switched to another way of transferring heat off the surface area of the processor: immersion cooling. It looks like science fiction to submerge computers in liquid, but it is not water. It is mineral oil.

TACC requires 200 staffers, many of whom work on user support, software, visualization, and AI. The core team that staffs the Data Center numbers 25, with at least one person there around the clock to watch for problems. There are people who “turn wrenches,” replacing parts and building out the hardware. Others mind the operating systems and security. Still others work on applications, scheduling, and support code tuning. Almost half of the staff are PhD-level research scientists.
Much of the staff is divided into support teams for projects within a given domain, such as the life sciences team, because they “just speak a different language,” Stanzione says. “I could have a physicist support a chemist or a materials scientist or an aerospace engineer because the math is all shared. If you speak differential equations you can work in those spaces, but when you start talking genome-wide association studies, there’s a whole different vernacular.” Besides the life sciences team, there is an AI data team, a visualization group, and experts who build out interfaces such as gateways and portals.
As for the users, scientists from some 450 institutions worldwide use TACC machines. The center is primarily funded by the National Science Foundation (NSF), which supports open science anywhere in the United States. Some 350 universities in the U.S. use TACC, but since science is often global, it is frequently the case that a U.S. project lead will have collaborators overseas. Many foreign collaborators are in Europe and Japan. Because TACC is funded mostly by the NSF, scientists in certain countries are not allowed to use TACC machines.
Stanzione says the diverse nature of supercomputing is what attracts many to the field. “I’m an electrical engineer by training, but I get to play all kinds of scientists during a regular day,” he says. “As we say, we do astronomy to zoology.” Traditionally, supercomputers have been used most in materials engineering and chemistry. But as the acquisition of digital data has gotten cheaper in recent decades, TACC has seen an influx of life sciences work. “Genomics, proteomics, the imagery from MRI, FMRI, cryoEM [cryogenic electron microscopy]—all of these techniques that create huge amounts of digital data increasingly cheaply mean you need big computers to process and analyze it,” Stanzione says.
The upshot of all this data flowing in for about the last seven years has been the emergence of AI to build statistical models to analyze it. “That’s fundamentally what AI is,” Stanzione says. “That’s probably the most exciting trend of the last few years: taking all the science we’ve done and bringing AI into how that works.
“We’re actually replacing parts of physics with what we’re calling surrogate models so we can do a faster scan in a space of parameters, simulate a possible hurricane, simulate every possible molecule for drug discovery. We scanned billions of molecules for interactions with COVID, every possible compound, and we used AI to accelerate that.”

The machines also take on other projects, including ramping up for every big natural disaster. “If there’s a hurricane in the gulf, odds are we’re [devoting] tens of thousands of cores … to hurricane forecasting,” Stanzione says. “[In the spring] we have a project with our neighbors up in Oklahoma who are doing storm chasing. We run fast forecasts of severe storms so they can send the tornado chasers out in the right direction at 4 a.m. every morning. In response to earthquakes, we do a lot of work around the infrastructure in response to natural hazards.” New earthquake-resistant building codes are the result of simulation data.
TACC systems have been used in work resulting in several Nobel Prizes. TACC machines were among the ones responsible for analyzing the data leading to the 2015 discovery by the Laser Interferometer Gravitational-Wave Observatory (LIGO) at Caltech and MIT of gravitational waves, created by the collision of two black holes. Albert Einstein predicted the existence of gravitational waves in 1916.
TACC also provided resources to the Large Hadron Collider in Switzerland. In 2012, the collider discovered the subatomic particle known as the Higgs boson, confirming the existence of the Higgs field, which gives mass to other fundamental particles such as electrons and quarks. “Almost every day, there was data coming off the colliders to look at,” Stanzione recalls. “Some days I get to be a biologist. Some days I’m a natural-hazards engineer. Some days we’re talking about astrophysics. Some days we’re discovering new materials for better batteries.”
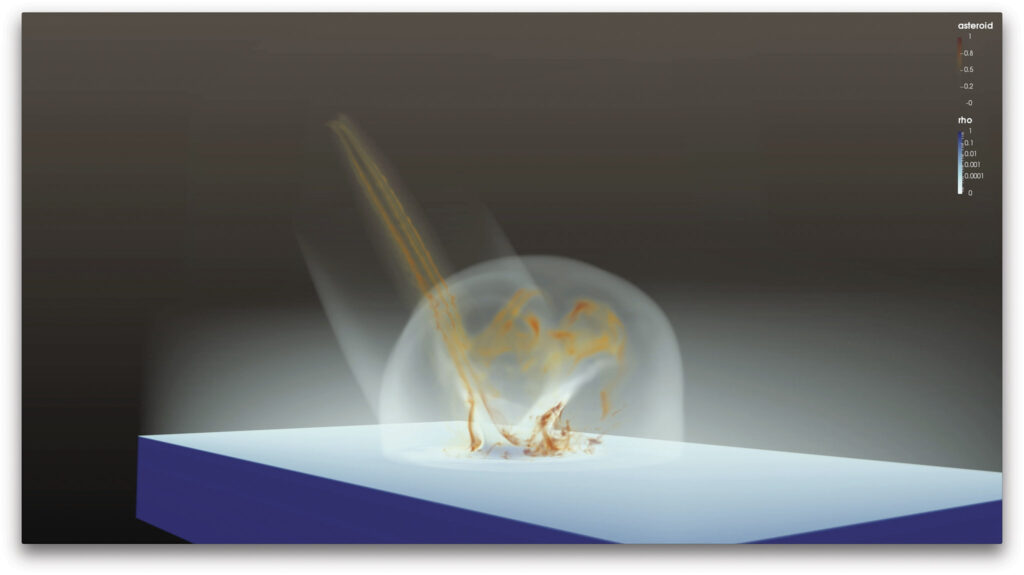
Video screens near the Data Center show a sample of work TACC machines are doing: a study of the containment of plasma for fusion, what happened after the Japanese earthquake and tsunami of 2011, a binary star merger, a simulation of a meteor hitting in the ocean off Seattle, severe storm formations, ocean currents around the Horn of Africa, a DNA helix in a drug discovery application, stitching together the color graphic and all the images from some of the first James Webb Space Telescope data being worked on at UT. “We have an endless variety of stuff that we get to do,” Stanzione says.
As data has gotten cheaper, the social sciences now are moving in to take advantage. “We have people instrumenting dancers with sensors all over their bodies who we store data for, things we never did 20 years ago,” Stanzione says. According to him, there’s probably not a department at the University that doesn’t have a tie to high performance computing.

In July, the National Science Foundation announced that, after many years of funding TACC’s supercomputers one system at a time, TACC would become a Leadership-Class Computing Facility. Stanzione calls it “a huge step forward for the NSF and computing,” and says they have been in the formal planning process for this for seven years and informally involved for 25 or 30 years. Moving TACC to what the NSF, in its understated way, terms “the major facilities account” puts it in an elite club of institutions such as the aforementioned Large Hadron Collider, LIGO, and several enormous telescopes, “things that run over decades.”
“From a scientific-capability perspective, we’re jumping an order of magnitude up in the size of computers we’re going to have, the size of the storage systems, and additional staffing,” Stanzione says. As mentioned, TACC is building a new data center in Round Rock just to house its next supercomputer, Horizon. The new data center, which the federal government is paying to customize, will be managed by a private data center company. TACC will remain on the Pickle Campus.
Horizon, coming online in 2026, will be the largest academic supercomputer dedicated to open-scientific research in the NSF portfolio, providing 10 times the performance of Frontera, the current NSF leadership-class computing system. For AI applications, the leap forward will be more than 100-fold over Frontera. SDC Austin will operate the facility. Upon completion, the campus will have a critical capacity of more than 85 megawatts and a footprint of 430,000 square feet.
Aside from a quantum leap in capability, there is also a consistency and sustainability aspect to the new NSF designation. Individual computers built with grant funding have a useful life of four to five years. “It’s like buying a laptop—they age out,” Stanzione explains. “If you’re partnering with one of these big telescopes like the Vera Rubin Observatory that’s going to operate for 30 years, there’s a huge risk for them if their data-processing plan relies on us and we have a four-year grant to run a machine. Now, we’re going to decade-scale operational plans with occasional refreshes to the hardware of the machine, which means we can be a more reliable partner for the other large things going on in science.”
Ecological work requires observations over decades. Astronomy work requires data to persist for a long time. In a show of leadership in that area, TACC recently sent a team to Puerto Rico to retrieve data from the Arecibo Observatory, long the world’s largest single-aperture telescope, before it shuts down. They came back with pallets of tapes with petabytes of data that have been collected since 1964 there. “If you’re making a billion-dollar investment in an instrument, you’re going to want to have both the processing capability and the data sustainability around that instrument,” Stanzione says. “For me, the first-order exciting thing is big new computers. That’s what drives us to do stuff. But for the national scientific enterprise, it’s consistent, sustainable data.”
Addressing AI within the context of supercomputing is basically redundant. “AI and the supercomputing infrastructures have converged,” Stanzione says. “We’ve been building a lot of human expertise supporting and scaling large AI runs, and now with the new facility will be building out more capacity to permanently host AI models for inference, so you can build a reliable service to tag an image or identify a molecule or get an AI inference on the most likely track of our hurricane or things like that.”
He adds, “We are where a lot of these techniques came from, and we look forward to partnering with more AI users around the campus as we both understand what it can do, how to use it responsibly, and how to minimize the energy it takes to run these big models. These are all core concerns for us, and that’s probably going to be a big growth area for us in years to come.”

CREDITS: Courtesy of the University; courtesy of TACC; courtesy of the University (2); courtesy of TACC (2)
Share this article










No comments
Be the first one to leave a comment.